As a foundational component of the original Synthesizer V Studio Pro, Dreamtonics introduced our Live Rendering System in 2020 which has since gone on to become a core part of the software.
But what is Live Rendering exactly and what benefits does it offer Synthesizer V users?
To answer this question, let’s have a look at some unique challenges facing vocal synthesis software today.
Vocal synthesis is fundamentally different from instrument synthesis, including most samplers and additive/subtractive/FM synthesis plugins. Most musical instruments react instantly when being plucked, pushed, struck or blown, and as the physical phenomenon causing the sound happens in an instant, it is relatively simple to replicate the sound using a real-time audio engine that causes only a very small delay. Typically, with proper algorithmic design and optimization methodologies, the latency between an incoming MIDI event and the audio that results from the plugin, often takes milliseconds.
However, synthesizing vocals is a much more complicated task. There are lyrics to process, and each word can span across multiple notes. Also, whilst singing, our brains need to know not only what notes to sing next, but the entire phrase to be able to adapt our sound-forming muscles (articulators) into the correct position. These challenges are no less for a program that tries to mimic the way humans sing. Even if the algorithm itself runs several times faster than typical real-time output, it is the vast amounts of look-ahead information required that makes it theoretically impossible to achieve truly real-time and low-latency vocal synthesis.
With this in mind, what’s the next best rendering and scheduling process we can offer users for a vocal synthesizer? There are mostly two ways:
1. By rendering an entire clip before a user starts playing it back.
2. When a user starts playing a clip back, start rendering the notes after the playhead.
However, there are pros and cons for each.
In the first instance, once a clip is fully rendered, playback can start immediately – although that could potentially take up to 10 seconds if a user is working on a very long clip.
In the second instance, the user unfortunately has to always wait before playing back, although the wait time is constant and can be kept reasonably low (~ 1 second) due to the rendering only needing to start a little before the playhead.
By the time our work on Synthesizer V had started, we envisioned a perfect scenario where the software would automatically decide which scheduling method to use, with a view to achieving the lowest possible wait time. However, after multiple iterations, it soon became apparent that either way would involve a compromise, resulting in stress and frustration.
Eventually, after months of intensive research and development, the Live Rendering System was ready! LRS was perhaps the most ambitious engineering project within the Synthesizer V software stack, with its complexity rivaling our realistic-sounding singing synthesis algorithm itself.
This is because LRS does more than automatically switching between the two renderer scheduling methods. Internally, it assigns different levels of rendering tasks priorities based on their potential importance to the user. They are as follows:
1. The notes right after the playhead receive the highest priority during playback.
2. The area displayed in the piano roll area receives the next highest priority level.
3. The rest of the project functions (not seen in the piano roll, and not being played) are counted as background tasks, only rendered if the necessary computing resources are available.
The layered design below shows that the synthesis engine always runs where the user needs to see/hear the result the most. In fact, LRS constantly checks the status of the workspace in the background, dynamically creating and managing rendering tasks.
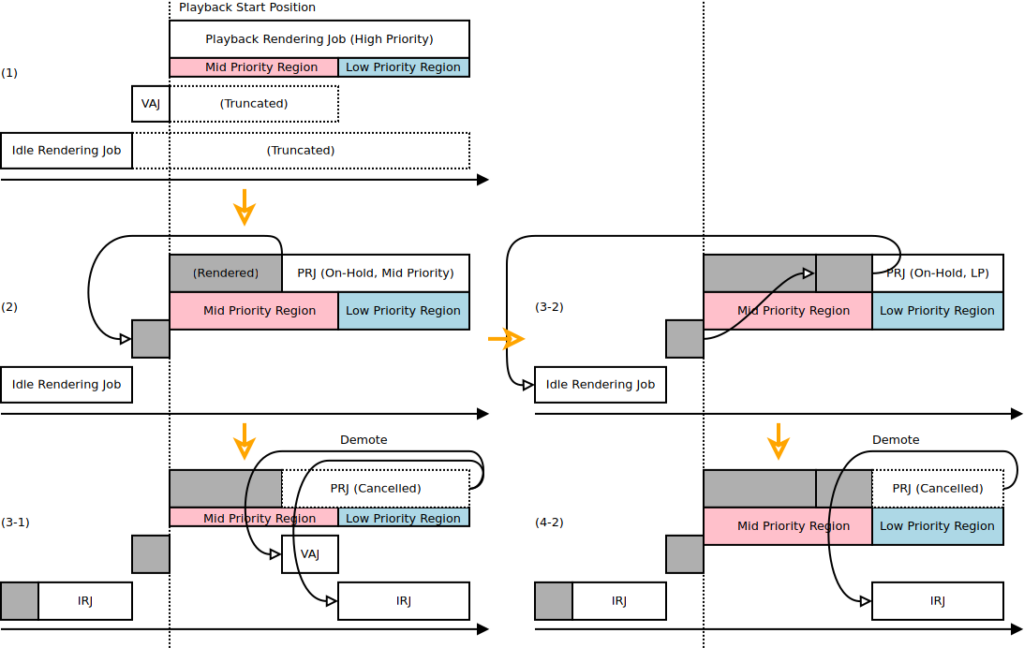
(schematics drawn while designing the Live Rendering System, made in 2019)
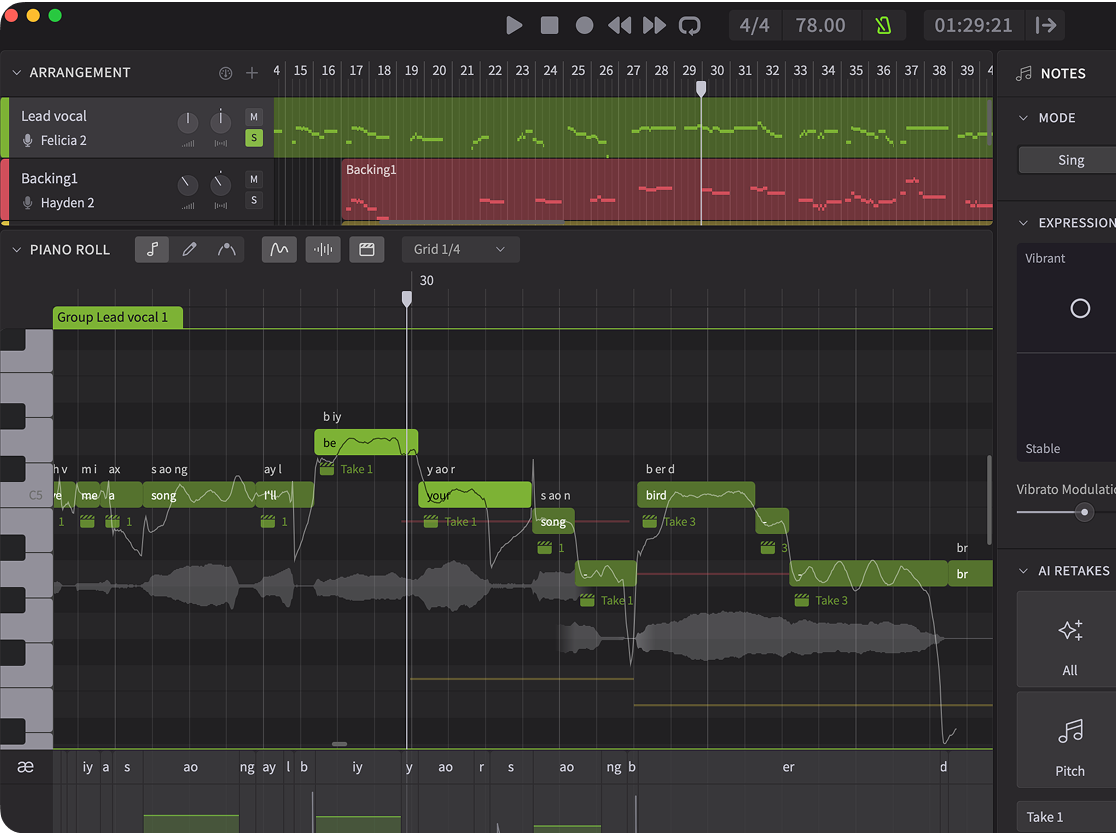
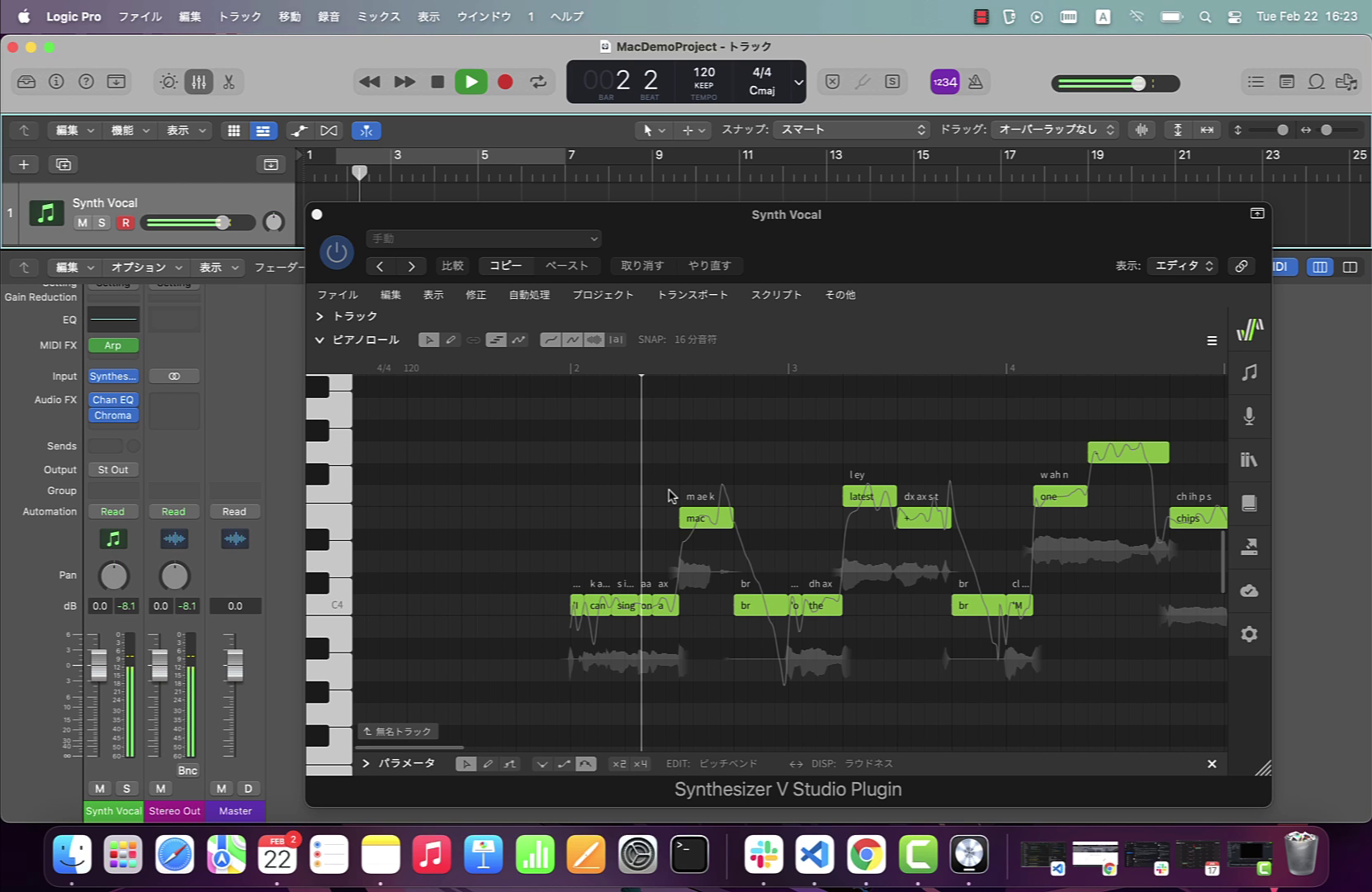
An additional benefit of LRS’ design is a readily available visualization that updates not just during playback, but as soon as any edit is made. The user can even see pitch curves and waveforms transform in real-time as they enter lyrics or move a note up or down. Furthermore, if they see anything that definitely doesn’t look right, they can immediately make edits without needing to hear the result.
In Synthesizer V Studio 2 Pro, LRS has been substantially improved and optimized to accommodate our latest deep learning-based vocal synthesis engine. Compared to version 1, version 2 now achieves an impressive 300% increase, thanks to the support for multithreading on modern devices.
However, behind the scenes it is not quite as simple as it sounds. With each rendering task now capable of using up all CPU cores, careful coordination is required to prevent even a low priority task from interfering with a more urgent task, such as during playback.
Find out more about Synthesizer V Studio 2 Pro, plus trial the software and any voice for 7-14 days HERE.